AI 없이 이메일 CTR 41% 올린 ATG의 추천 엔진 구축법

ATG Entertainment의 시니어 데이터 사이언티스트 Oliver Marley는 정적인 8칸짜리 이메일 캠페인을 수천 개의 개인화 경험으로 바꾸는 작업을 맡았어요. 공연 프로듀서는 자기 쇼가 최대한 노출되길 원했고, 고객은 자기 취향에 맞는 콘텐츠만 받고 싶어했죠. 둘 사이에서 마케팅팀이 매번 끼어 있는 구조였습니다.
그가 Activate Summit 발표에서 공개한 숫자는 단순했어요. 30개 이상의 캠페인 테스트에서 클릭률 41% 증가, 그리고 이 결과를 만든 추천 모델에는 AI가 한 줄도 들어가 있지 않았어요. 화려한 LLM이 아니라 collaborative filtering이라는, 이미 수십 년 된 기법 하나로 끝낸 일이었어요.
Iterable 블로그에 정리된 이 케이스의 핵심은 기술이 아니라 순서예요. 추천 엔진을 먼저 짜지 않고, 고객 경험을 먼저 정의한 다음 그걸 받쳐줄 가장 단순한 시스템을 깔았다는 점. 한국의 B2C CRM 담당자라면 “우리도 추천을 넣고 싶은데 데이터팀이 없어요”라고 미루던 프로젝트가, 사실 데이터팀 없이도 시작 가능했다는 사실을 확인하게 될 거예요.
ATG가 거쳐 간 5단계 파이프라인과 그 안에서 배운 5가지 교훈을 차례로 풀어볼게요.
왜 개인화 프로젝트는 시작도 못 하고 멈추는가
많은 팀이 개인화에 실패하는 건 추천 알고리즘이 부족해서가 아니에요. ATG는 정체의 원인을 세 가지로 정리합니다.
첫 번째는 마인드셋이에요. “제품 중심 마케팅”인지 “고객 중심 마케팅”인지의 문제죠. 각 부서 이해관계자들이 자기 상품 노출을 극대화하려다 보니, 결과적으로 고객은 더 많은 콘텐츠를 받지만 더 좋은 콘텐츠를 받지는 못해요. ATG는 이 시점에서 질문을 바꿉니다. “이 고객이 다음에 무엇을 보고 싶어할까?”
두 번째는 데이터 기반이에요. 고객 데이터만 있다고 개인화가 되는 게 아니더라고요. ATG가 정리한 세 가지 조건은 이거예요. 접근 가능한 행동 데이터, 상품/카탈로그 데이터, 그리고 둘을 잇는 시스템. 이 세 개가 한 줄로 정리되지 않으면 추천 엔진은 시작도 못 해요.
세 번째는 실행이에요. 인사이트가 대시보드에 떠 있어도 캠페인 안에서 자동으로 작동하지 않으면 가치가 없어요. 템플릿, 프로세스, 동적 콘텐츠를 받쳐줄 인프라가 같이 따라와야 한다는 얘기예요.
“Top Picks” 캠페인: 8칸 포맷은 그대로, 채우는 방식만 바꾸다
영감은 평범한 곳에서 왔어요. 스트리밍 서비스, 이커머스, 소셜 네트워크가 다 쓰고 있는 “당신을 위한 추천”, “이번 주 톱 픽” 같은 섹션. ATG는 이 패턴을 그대로 이메일로 가져옵니다.
결과물의 이름은 “Top Picks”였어요. 핵심 변화는 단순합니다. 모든 구독자에게 같은 8개 쇼를 보내는 대신, 고객마다 본인의 관심사에 맞춰 정렬된 8개 쇼를 보낸 거예요.
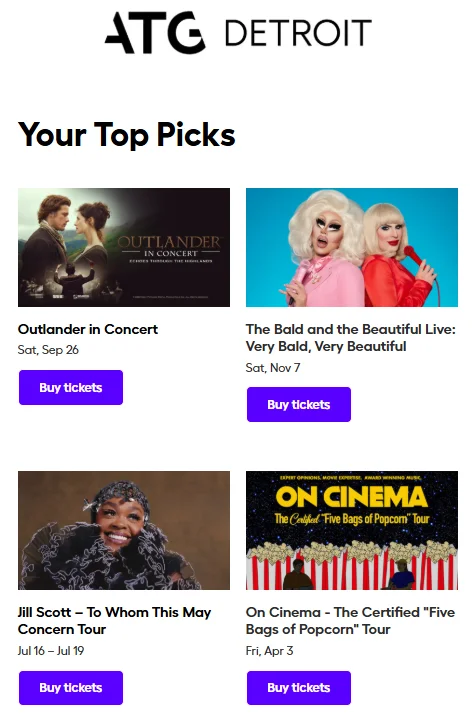

ATG가 정리한 “기존 캠페인 vs Top Picks” 비교는 이래요.
- 기존: 마케팅팀이 8개 쇼를 수동 선정 / Top Picks: 고객마다 추천이 생성됨
- 기존: 비즈니스 우선순위 기반 콘텐츠 / Top Picks: 고객 관련성 기반 콘텐츠
- 기존: 모두에게 같은 이메일 / Top Picks: 수천 개의 고유한 조합
- 기존: 수동 포맷팅·업데이트 / Top Picks: 동적 콘텐츠 자동 채움
중요한 건 포맷은 바꾸지 않았다는 점이에요. 고객 입장에서는 여전히 8개 공연이 추천되는 익숙한 메일. 다만 그 8개 자리에 100개 넘는 진행 중인 쇼 풀에서 뽑힌 콘텐츠가 들어간다는 차이만 있었죠.
결과: 30개 캠페인 테스트, CTR +41%
구체 수치는 이래요. 30회 이상의 캠페인 테스트에서 “Top Picks” 방식이 정적 캠페인을 일관되게 능가했어요. 클릭률 41% 증가, 전환 성과 개선, 그리고 전체 공연 카탈로그에 걸쳐 노출이 더 고르게 퍼졌다고 합니다.
부수 효과도 컸어요. 캠페인을 만들 때 일일이 쇼를 드래그·드롭하고 포맷을 다시 잡던 수작업이 사라졌거든요. 마케터의 손이 추천 로직이 아니라 “오늘 어떤 캠페인을 보낼까”에만 가도록 바뀐 거예요.
추천 엔진 파이프라인 5단계
ATG의 엔진은 결과만 보면 정교해 보이지만 실제 구조는 직선적이에요. 다섯 단계로 쪼개집니다.
1단계: 고객 데이터와 카탈로그 데이터를 한 곳에 모은다
두 종류의 핵심 데이터가 시작점이에요. 티켓 구매·예약 이력 같은 거래 데이터, 그리고 공연 제목·날짜·장소·재고 같은 카탈로그 데이터. ATG는 둘 다 Snowflake에 저장해서 고객 활동과 공연 인벤토리의 단일 진실(single source of truth)을 만들었어요. 이 기반 없이는 “고객 취향”과 “이용 가능한 콘텐츠”가 다른 시스템에 흩어져 있어서 개인화 자체가 어려워져요.
2단계: 추천을 생성한다 (collaborative filtering)
복잡한 AI 모델을 만들지 않았어요. 시작점은 collaborative filtering이라는 단순한 기법. 두 공연의 관객층이 자주 겹친다면, 그 두 공연은 비슷한 관심 패턴을 공유할 가능성이 크다는 가정이에요.
예를 들면 이런 식이에요.
- The Lion King 티켓을 산 고객은 Wicked에도 관심 있을 수 있다
- 특정 코미디언 팬은 비슷한 스타일의 다른 공연자에게도 반응한다
- 극장 관객은 장르별로 반복 선호를 보인다
ATG는 이런 관객 관계로부터 고객별 추천 공연 순위를 만들어 냅니다.
3단계: 추천을 CRM으로 push한다
생성된 추천 데이터는 마케터가 실제로 쓸 수 있어야 해요. ATG는 Iterable Smart Ingest를 사용해서 추천 데이터를 고객 프로필에 직접 밀어 넣었어요. 송신 시점에 별도 설정 없이 개인화 콘텐츠가 자동으로 끼워지는 구조죠.
이게 중요한 이유는, 추천을 “별도 시스템”이 아니라 “고객 프로필의 일부”로 만들었다는 점이에요. 마케터가 캠페인을 짤 때 추천 모듈을 따로 다룰 필요가 없어진 거예요.
4단계: 추천 피로감을 막는다 (exposure ledger)
가장 영리한 부분 중 하나가 ATG가 “exposure ledger”라 부르는 장치예요. 추천 엔진의 흔한 함정은 같은 콘텐츠를 반복해서 들이미는 거거든요. 어떤 고객이 한 공연을 좋아할 수 있지만, 매주 같은 추천을 받으면 피로해져요.
ATG는 네 가지를 트래킹합니다.
- 고객이 이미 본 추천
- 클릭한 추천
- 무시한 추천
- 콘텐츠가 노출된 빈도
이 신호들이 다음번 추천 순위에 다시 들어가요. 결과적으로 추천 시스템이 고객 행동과 함께 진화하는 셈이죠. 같은 답을 무한 반복하지 않는 추천 엔진.
5단계: 이메일에 추천을 노출한다 (모듈러 템플릿)
마지막은 “보이는 방식”이에요. ATG는 추천 로직과 이메일 디자인을 분리합니다. Iterable Snippets를 써서 두 개의 레이어를 만들었어요. 한쪽은 추천·카탈로그 로직을 담당, 다른 한쪽은 쇼 카드·콘텐츠 블록의 시각 표현을 담당.
이렇게 분리해 두면 템플릿 유지보수가 쉬워지고, 마케터가 추천 로직을 건드리지 않고도 크리에이티브만 업데이트할 수 있어요. 개인화 노력이 늘어나도 시스템이 함께 확장되는 구조죠.
매번 같은 이메일로 보이지 않게: 변화의 3가지 원칙
개인화가 확장되면 새로운 문제가 생겨요. 추천은 정확한데, 매번 같은 구조로 오면 결국 “비슷한 이메일” 같아 보이는 거예요. ATG는 세 가지 방향으로 다양성을 만듭니다.
첫 번째, 콘텐츠 타입을 섞는다. 추천에만 의존하지 않고 “Recommended for You”, “Coming Up”, “Now On Sale” 같은 섹션을 결합해 개인화와 발견(discovery)의 균형을 맞춰요.
두 번째, Collections로 동적으로 정리한다. 시장, 가용성, 공연 일정 같은 기준으로 콘텐츠를 묶어서 한 캠페인 안에서 개인화 콘텐츠와 맥락형 콘텐츠를 같이 보낼 수 있게 합니다.
세 번째, 시각적 변화도 준다. 콘텐츠는 경험의 일부일 뿐이라는 인식 아래, 다양한 레이아웃·표현 스타일을 실험해서 추천이 겹쳐도 이메일이 신선하게 느껴지도록 했어요.
핵심은 이거예요. 추천이 “고객이 무엇을 볼지”를 결정한다면, 전체 경험은 “고객이 계속 반응할지”를 결정해요.
ATG가 얻은 5가지 교훈
엔터테인먼트 마케팅을 넘어 적용되는 다섯 가지 교훈이에요.
첫째, 고객 경험에서 시작하라. ATG는 “Top Picks”라는 경험을 먼저 정의한 다음, 그걸 받쳐줄 기술을 짰어요. 반대 순서로 가면 보통 실패합니다.
둘째, 단순하게 시작하라. collaborative filtering 하나로 측정 가능한 결과가 나왔어요. 복잡한 AI나 수년간의 개발 없이도 가능했죠.
셋째, 모듈러 시스템을 짜라. 추천 로직과 표현을 분리해 두면 캠페인 관리·업데이트·확장이 다 쉬워져요.
넷째, 자기 제약에 맞춰 설계하라. 모든 조직의 데이터·리소스·요구사항이 다 다르거든요. 가장 좋은 솔루션은 우리 환경에 맞는 솔루션이에요.
다섯째, 결과가 정렬을 만든다. 긍정적인 테스트 결과가 나오자 이해관계자 대화가 “의견”에서 “증거”로 바뀌었어요. 고객 중심 접근에 대한 동의를 만드는 가장 쉬운 방법이었다고 합니다.
다음 단계: 실시간 시그널과 전면 확장
ATG는 지금의 추천 엔진을 “기반”으로 봅니다. 다음에 풀고 싶은 과제는 세 가지예요.
- 브라우징 행동 통합: 구매가 일어나기 전에 고객 관심사를 더 깊이 이해하기
- 추천 latency 단축: Iterable Data Feeds를 활용해 송신 직전에 추천을 가져와서 콘텐츠가 가장 최신 행동을 반영하게 만들기
- 개인화 커버리지 확장: 동적 콘텐츠를 모든 캠페인의 표준 구성요소로 만들기
목표는 단순해요. 마케팅 프로그램 전체에 걸쳐 “고객 관련성”을 손쉽게 확장 가능한 상태로 만드는 것.
마무리: 추천 엔진은 생각보다 가까이 있다
많은 마케터가 개인화에 정교한 AI, 거대한 팀, 완벽한 데이터가 필요하다고 가정해요. ATG의 경험은 정반대를 말합니다. 가장 큰 돌파구는 더 정교한 알고리즘이 아니라, “팔아야 하는 것”에서 “고객이 보고 싶어하는 것”으로 질문을 바꾼 거였어요.
명확한 고객 경험을 정의하고, 그걸 받쳐줄 가장 단순한 추천 모델을 만들고, 반복하면서 개선한다. 이 순서가 측정 가능한 결과를 만든 출발점이었어요. 추천 엔진을 검토 중인 팀이라면 가져갈 메시지는 하나예요. 경험을 먼저, 그다음에 가장 단순한 시스템, 거기서부터 개선.
본 글은 Iterable에서 발행한 원문 How ATG Entertainment Built a Recommendation Engine at Scale을 번역한 것입니다. 원문의 의도와 다를 수 있으며, 정확한 내용은 원문을 참고하세요.
